12. Parallelization
Due to the computationally-intensive nature of Monte Carlo methods, there has been an ever-present interest in parallelizing such simulations. Even in the first paper on the Monte Carlo method, John Metropolis and Stanislaw Ulam recognized that solving the Boltzmann equation with the Monte Carlo method could be done in parallel very easily whereas the deterministic counterparts for solving the Boltzmann equation did not offer such a natural means of parallelism. With the introduction of vector computers in the early 1970s, general-purpose parallel computing became a reality. In 1972, Troubetzkoy et al. designed a Monte Carlo code to be run on the first vector computer, the ILLIAC-IV [Troubetzkoy]. The general principles from that work were later refined and extended greatly through the work of Forrest Brown in the 1980s. However, as Brown’s work shows, the single-instruction multiple-data (SIMD) parallel model inherent to vector processing does not lend itself to the parallelism on particles in Monte Carlo simulations. Troubetzkoy et al. recognized this, remarking that “the order and the nature of these physical events have little, if any, correlation from history to history,” and thus following independent particle histories simultaneously using a SIMD model is difficult.
The difficulties with vector processing of Monte Carlo codes led to the adoption of the single program multiple data (SPMD) technique for parallelization. In this model, each different process tracks a particle independently of other processes, and between fission source generations the processes communicate data through a message-passing interface. This means of parallelism was enabled by the introduction of message-passing standards in the late 1980s and early 1990s such as PVM and MPI. The SPMD model proved much easier to use in practice and took advantage of the inherent parallelism on particles rather than instruction-level parallelism. As a result, it has since become ubiquitous for Monte Carlo simulations of transport phenomena.
Thanks to the particle-level parallelism using SPMD techniques, extremely high parallel efficiencies could be achieved in Monte Carlo codes. Until the last decade, even the most demanding problems did not require transmitting large amounts of data between processors, and thus the total amount of time spent on communication was not significant compared to the amount of time spent on computation. However, today’s computing power has created a demand for increasingly large and complex problems, requiring a greater number of particles to obtain decent statistics (and convergence in the case of criticality calculations). This results in a correspondingly higher amount of communication, potentially degrading the parallel efficiency. Thus, while Monte Carlo simulations may seem embarrassingly parallel, obtaining good parallel scaling with large numbers of processors can be quite difficult to achieve in practice.
12.1. Fission Bank Algorithms
12.1.1. Master-Slave Algorithm
Monte Carlo particle transport codes commonly implement a SPMD model by having one master process that controls the scheduling of work and the remaining processes wait to receive work from the master, process the work, and then send their results to the master at the end of the simulation (or a source iteration in the case of an eigenvalue calculation). This idea is illustrated in Communication pattern in master-slave algorithm..
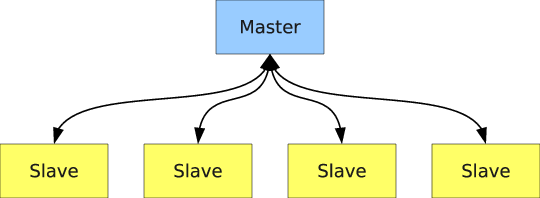
Figure 10: Communication pattern in master-slave algorithm.
Eigenvalue calculations are slightly more difficult to parallelize than fixed source calculations since it is necessary to converge on the fission source distribution and eigenvalue before tallying. In the Method of Successive Generations, to ensure that the results are reproducible, one must guarantee that the process by which fission sites are randomly sampled does not depend on the number of processors. What is typically done is the following:
Each compute node sends its fission bank sites to a master process;
2. The master process sorts or orders the fission sites based on a unique identifier;
3. The master process samples \(N\) fission sites from the ordered array of \(M\) sites; and
4. The master process broadcasts all the fission sites to the compute nodes.
The first and last steps of this process are the major sources of communication overhead between cycles. Since the master process must receive \(M\) fission sites from the compute nodes, the first step is necessarily serial. This step can be completed in \(O(M)\) time. The broadcast step can benefit from parallelization through a tree-based algorithm. Despite this, the communication overhead is still considerable.
To see why this is the case, it is instructive to look at a hypothetical example. Suppose that a calculation is run with \(N = 10,000,000\) neutrons across 64 compute nodes. On average, \(M = 10,000,000\) fission sites will be produced. If the data for each fission site consists of a spatial location (three 8 byte real numbers) and a unique identifier (one 4 byte integer), the memory required per site is 28 bytes. To broadcast 10,000,000 source sites to 64 nodes will thus require transferring 17.92 GB of data. Since each compute node does not need to keep every source site in memory, one could modify the algorithm from a broadcast to a scatter. However, for practical reasons (e.g. work self-scheduling), this is normally not done in production Monte Carlo codes.
12.1.2. Nearest Neighbors Algorithm
To reduce the amount of communication required in a fission bank synchronization algorithm, it is desirable to move away from the typical master-slave algorithm to an algorithm whereby the compute nodes communicate with one another only as needed. This concept is illustrated in Communication pattern in nearest neighbor algorithm..

Figure 11: Communication pattern in nearest neighbor algorithm.
Since the source sites for each cycle are sampled from the fission sites banked from the previous cycle, it is a common occurrence for a fission site to be banked on one compute node and sent back to the master only to get sent back to the same compute node as a source site. As a result, much of the communication inherent in the algorithm described previously is entirely unnecessary. By keeping the fission sites local, having each compute node sample fission sites, and sending sites between nodes only as needed, one can cut down on most of the communication. One algorithm to achieve this is as follows:
1. An exclusive scan is performed on the number of sites banked, and the total number of fission bank sites is broadcasted to all compute nodes. By picturing the fission bank as one large array distributed across multiple nodes, one can see that this step enables each compute node to determine the starting index of fission bank sites in this array. Let us call the starting and ending indices on the \(i\)-th node \(a_i\) and \(b_i\), respectively;
2. Each compute node samples sites at random from the fission bank using the same starting seed. A separate array on each compute node is created that consists of sites that were sampled local to that node, i.e. if the index of the sampled site is between \(a_i\) and \(b_i\), it is set aside;
3. If any node sampled more than \(N/p\) fission sites where \(p\) is the number of compute nodes, the extra sites are put in a separate array and sent to all other compute nodes. This can be done efficiently using the allgather collective operation;
4. The extra sites are divided among those compute nodes that sampled fewer than \(N/p\) fission sites.
However, even this algorithm exhibits more communication than necessary since the allgather will send fission bank sites to nodes that don’t necessarily need any extra sites.
One alternative is to replace the allgather with a series of sends. If \(a_i\) is less than \(iN/p\), then send \(iN/p - a_i\) sites to the left adjacent node. Similarly, if \(a_i\) is greater than \(iN/p\), then receive \(a_i - iN/p\) from the left adjacent node. This idea is applied to the fission bank sites at the end of each node’s array as well. If \(b_i\) is less than \((i+1)N/p\), then receive \((i+1)N/p - b_i\) sites from the right adjacent node. If \(b_i\) is greater than \((i+1)N/p\), then send \(b_i - (i+1)N/p\) sites to the right adjacent node. Thus, each compute node sends/receives only two messages under normal circumstances.
The following example illustrates how this algorithm works. Let us suppose we are simulating \(N = 1000\) neutrons across four compute nodes. For this example, it is instructive to look at the state of the fission bank and source bank at several points in the algorithm:
The beginning of a cycle where each node has \(N/p\) source sites;
The end of a cycle where each node has accumulated fission sites;
3. After sampling, where each node has some amount of source sites usually not equal to \(N/p\);
4. After redistribution, each node again has \(N/p\) source sites for the next cycle;
At the end of each cycle, each compute node needs 250 fission bank sites to continue on the next cycle. Let us suppose that \(p_0\) produces 270 fission banks sites, \(p_1\) produces 230, \(p_2\) produces 290, and \(p_3\) produces 250. After each node samples from its fission bank sites, let’s assume that \(p_0\) has 260 source sites, \(p_1\) has 215, \(p_2\) has 280, and \(p_3\) has 245. Note that the total number of sampled sites is 1000 as needed. For each node to have the same number of source sites, \(p_0\) needs to send its right-most 10 sites to \(p_1\), and \(p_2\) needs to send its left-most 25 sites to \(p_1\) and its right-most 5 sites to \(p_3\). A schematic of this example is shown in Example of nearest neighbor algorithm.. The data local to each node is given a different hatching, and the cross-hatched regions represent source sites that are communicated between adjacent nodes.
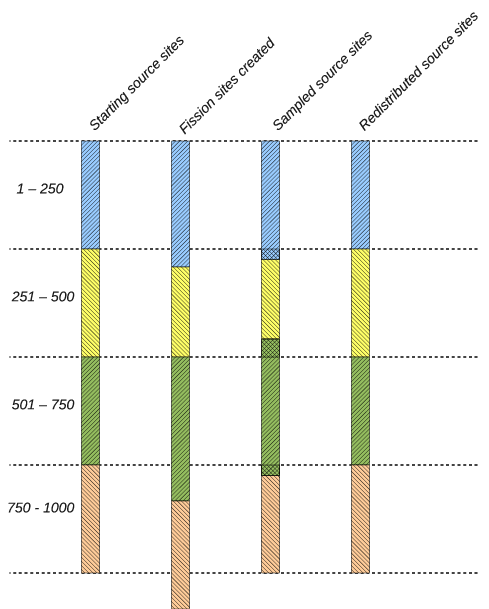
Figure 12: Example of nearest neighbor algorithm.
12.1.3. Cost of Master-Slave Algorithm
While the prior considerations may make it readily apparent that the novel algorithm should outperform the traditional algorithm, it is instructive to look at the total communication cost of the novel algorithm relative to the traditional algorithm. This is especially so because the novel algorithm does not have a constant communication cost due to stochastic fluctuations. Let us begin by looking at the cost of communication in the traditional algorithm
As discussed earlier, the traditional algorithm is composed of a series of sends and typically a broadcast. To estimate the communication cost of the algorithm, we can apply a simple model that captures the essential features. In this model, we assume that the time that it takes to send a message between two nodes is given by \(\alpha + (sN)\beta\), where \(\alpha\) is the time it takes to initiate the communication (commonly called the latency), \(\beta\) is the transfer time per unit of data (commonly called the bandwidth), \(N\) is the number of fission sites, and \(s\) is the size in bytes of each fission site.
The first step of the traditional algorithm is to send \(p\) messages to the master node, each of size \(sN/p\). Thus, the total time to send these messages is
Generally, the best parallel performance is achieved in a weak scaling scheme where the total number of histories is proportional to the number of processors. However, we see that when \(N\) is proportional to \(p\), the time to send these messages increases proportionally with \(p\).
Estimating the time of the broadcast is complicated by the fact that different MPI implementations may use different algorithms to perform collective communications. Worse yet, a single implementation may use a different algorithm depending on how many nodes are communicating and the size of the message. Using multiple algorithms allows one to minimize latency for small messages and minimize bandwidth for long messages.
We will focus here on the implementation of broadcast in the MPICH implementation. For short messages, MPICH uses a binomial tree algorithm. In this algorithm, the root process sends the data to one node in the first step, and then in the subsequent, both the root and the other node can send the data to other nodes. Thus, it takes a total of \(\lceil \log_2 p \rceil\) steps to complete the communication. The time to complete the communication is
This algorithm works well for short messages since the latency term scales logarithmically with the number of nodes. However, for long messages, an algorithm that has lower bandwidth has been proposed by Barnett and implemented in MPICH. Rather than using a binomial tree, the broadcast is divided into a scatter and an allgather. The time to complete the scatter is :math:` log_2 p : alpha + frac{p-1}{p} Nbeta` using a binomial tree algorithm. The allgather is performed using a ring algorithm that completes in \(p-1) \alpha + \frac{p-1}{p} N\beta\). Thus, together the time to complete the broadcast is
The fission bank data will generally exceed the threshold for switching from short to long messages (typically 8 kilobytes), and thus we will use the equation for long messages. Adding equations (1) and (3), the total cost of the series of sends and the broadcast is
12.1.4. Cost of Nearest Neighbor Algorithm
With the communication cost of the traditional fission bank algorithm quantified, we now proceed to discuss the communication cost of the proposed algorithm. Comparing the cost of communication of this algorithm with the traditional algorithm is not trivial due to fact that the cost will be a function of how many fission sites are sampled on each node. If each node samples exactly \(N/p\) sites, there will not be communication between nodes at all. However, if any one node samples more or less than \(N/p\) sites, the deviation will result in communication between logically adjacent nodes. To determine the expected deviation, one can analyze the process based on the fundamentals of the Monte Carlo process.
The steady-state neutron transport equation for a multiplying medium can be written in the form of an eigenvalue problem,
where \(\mathbf{r}\) is the spatial coordinates of the neutron, \(S(\mathbf{r})\) is the source distribution defined as the expected number of neutrons born from fission per unit phase-space volume at \(\mathbf{r}\), \(F( \mathbf{r}' \rightarrow \mathbf{r})\) is the expected number of neutrons born from fission per unit phase space volume at \(\mathbf{r}\) caused by a neutron at \(\mathbf{r}\), and \(k\) is the eigenvalue. The fundamental eigenvalue of equation (5) is known as \(k_{eff}\), but for simplicity we will simply refer to it as \(k\).
In a Monte Carlo criticality simulation, the power iteration method is applied iteratively to obtain stochastic realizations of the source distribution and estimates of the \(k\)-eigenvalue. Let us define \(\hat{S}^{(m)}\) to be the realization of the source distribution at cycle \(m\) and \(\hat{\epsilon}^{(m)}\) be the noise arising from the stochastic nature of the tracking process. We can write the stochastic realization in terms of the fundamental source distribution and the noise component as (see Brissenden and Garlick):
where \(N\) is the number of particle histories per cycle. Without loss of generality, we shall drop the superscript notation indicating the cycle as it is understood that the stochastic realization is at a particular cycle. The expected value of the stochastic source distribution is simply
since \(E \left[ \hat{\epsilon}(\mathbf{r})\right] = 0\). The noise in the source distribution is due only to \(\hat{\epsilon}(\mathbf{r})\) and thus the variance of the source distribution will be
Lastly, the stochastic and true eigenvalues can be written as integrals over all phase space of the stochastic and true source distributions, respectively, as
noting that \(S(\mathbf{r})\) is \(O(1)\). One should note that the expected value \(k\) calculated by Monte Carlo power iteration (i.e. the method of successive generations) will be biased from the true fundamental eigenvalue of equation (5) by \(O(1/N)\) (see Brissenden and Garlick), but we will assume henceforth that the number of particle histories per cycle is sufficiently large to neglect this bias.
With this formalism, we now have a framework within which we can determine the properties of the distribution of expected number of fission sites. The explicit form of the source distribution can be written as
where \(\mathbf{r}_i\) is the spatial location of the \(i\)-th fission site, \(w_i\) is the statistical weight of the fission site at \(\mathbf{r}_i\), and \(M\) is the total number of fission sites. It is clear that the total weight of the fission sites is simply the integral of the source distribution. Integrating equation (6) over all space, we obtain
Substituting the expressions for the stochastic and true eigenvalues from equation (9), we can relate the stochastic eigenvalue to the integral of the noise component of the source distribution as
Since the expected value of \(\hat{\epsilon}\) is zero, the expected value of its integral will also be zero. We thus see that the variance of the integral of the source distribution, i.e. the variance of the total weight of fission sites produced, is directly proportional to the variance of the integral of the noise component. Let us call this term \(\sigma^2\) for simplicity:
The actual value of \(\sigma^2\) will depend on the physical nature of the problem, whether variance reduction techniques are employed, etc. For instance, one could surmise that for a highly scattering problem, \(\sigma^2\) would be smaller than for a highly absorbing problem since more collisions will lead to a more precise estimate of the source distribution. Similarly, using implicit capture should in theory reduce the value of \(\sigma^2\).
Let us now consider the case where the \(N\) total histories are divided up evenly across \(p\) compute nodes. Since each node simulates \(N/p\) histories, we can write the source distribution as
Integrating over all space and simplifying, we can obtain an expression for the eigenvalue on the \(i\)-th node:
It is easy to show from this expression that the stochastic realization of the global eigenvalue is merely the average of these local eigenvalues:
As was mentioned earlier, at the end of each cycle one must sample \(N\) sites from the \(M\) sites that were created. Thus, the source for the next cycle can be seen as the fission source from the current cycle divided by the stochastic realization of the eigenvalue since it is clear from equation (9) that \(\hat{k} = M/N\). Similarly, the number of sites sampled on each compute node that will be used for the next cycle is
While we know conceptually that each compute node will under normal circumstances send two messages, many of these messages will overlap. Rather than trying to determine the actual communication cost, we will instead attempt to determine the maximum amount of data being communicated from one node to another. At any given cycle, the number of fission sites that the \(j\)-th compute node will send or receive (\(\Lambda_j\)) is
Noting that \(jN/p\) is the expected value of the summation, we can write the expected value of \(\Lambda_j\) as the mean absolute deviation of the summation:
where \(\text{MD}\) indicates the mean absolute deviation of a random variable. The mean absolute deviation is an alternative measure of variability.
In order to ascertain any information about the mean deviation of \(M_i\), we need to know the nature of its distribution. Thus far, we have said nothing of the distributions of the random variables in question. The total number of fission sites resulting from the tracking of \(N\) neutrons can be shown to be normally distributed via the Central Limit Theorem (provided that \(N\) is sufficiently large) since the fission sites resulting from each neutron are “sampled” from independent, identically-distributed random variables. Thus, \(\hat{k}\) and \(\int \hat{S} (\mathbf{r}) \: d\mathbf{r}\) will be normally distributed as will the individual estimates of these on each compute node.
Next, we need to know what the distribution of \(M_i\) in equation (17) is or, equivalently, how \(\hat{k}_i / \hat{k}\) is distributed. The distribution of a ratio of random variables is not easy to calculate analytically, and it is not guaranteed that the ratio distribution is normal if the numerator and denominator are normally distributed. For example, if \(X\) is a standard normal distribution and \(Y\) is also standard normal distribution, then the ratio \(X/Y\) has the standard Cauchy distribution. The reader should be reminded that the Cauchy distribution has no defined mean or variance. That being said, Geary has shown that, for the case of two normal distributions, if the denominator is unlikely to assume values less than zero, then the ratio distribution is indeed approximately normal. In our case, \(\hat{k}\) absolutely cannot assume a value less than zero, so we can be reasonably assured that the distribution of \(M_i\) will be normal.
For a normal distribution with mean \(\mu\) and distribution function \(f(x)\), it can be shown that
and thus the mean absolute deviation is \(\sqrt{2/\pi}\) times the standard deviation. Therefore, to evaluate the mean absolute deviation of \(M_i\), we need to first determine its variance. Substituting equation (16) into equation (17), we can rewrite \(M_i\) solely in terms of \(\hat{k}_1, \dots, \hat{k}_p\):
Since we know the variance of \(\hat{k}_i\), we can use the error propagation law to determine the variance of \(M_i\):
where the partial derivatives are evaluated at \(\hat{k}_j = k\). Since \(\hat{k}_j\) and \(\hat{k}_m\) are independent if \(j \neq m\), their covariance is zero and thus the second term cancels out. Evaluating the partial derivatives, we obtain
Through a similar analysis, one can show that the variance of \(\sum_{i=1}^j M_i\) is
Thus, the expected amount of communication on node \(j\), i.e. the mean absolute deviation of \(\sum_{i=1}^j M_i\) is proportional to
This formula has all the properties that one would expect based on intuition:
1. As the number of histories increases, the communication cost on each node increases as well;
2. If \(p=1\), i.e. if the problem is run on only one compute node, the variance will be zero. This reflects the fact that exactly \(N\) sites will be sampled if there is only one node.
3. For \(j=p\), the variance will be zero. Again, this says that when you sum the number of sites from each node, you will get exactly \(N\) sites.
We can determine the node that has the highest communication cost by differentiating equation (25) with respect to \(j\), setting it equal to zero, and solving for \(j\). Doing so yields \(j_{\text{max}} = p/2\). Interestingly, substituting \(j = p/2\) in equation (25) shows us that the maximum communication cost is actually independent of the number of nodes:
References
E. Troubetzkoy, H. Steinberg, and M. Kalos, “Monte Carlo Radiation Penetration Calculations on a Parallel Computer,” Trans. Am. Nucl. Soc., 17, 260 (1973).